Are CRDTs suitable for shared editing?
CRDTs are often praised as the "holy grail" for building collaborative applications because they don't require a central authority to resolve sync conflicts. They open up new possibilities to scale the backend infrastructure and are also well-suited as a data-model for distributed apps that don't require a server at all.
However, several text editor developers report not to use them because they impose a too significant overhead.
Just recently, Marijn Haverbeke wrote about his considerations against using CRDTs as a data model for CodeMirror 6:
[..] the cost of such a representation is significant, and in the end, I judged the requirement for converging positions to be too obscure to justify that level of extra complexity and memory use. (source)
The Xi Editor used a CRDT as its data model to allow different processes (syntax highlighter, type checker, ..) to concurrently access the editor state without blocking the process. They reverted to a synchronous model because ..
[..] CRDT is not pulling its (considerable) weight. (source)
Apparently, everyone recognizes that CRDTs have a lot of potential, but concluded that the memory overhead of using them must be too expensive for real-world applications.
They bring up a fair point. Most CRDTs assign a unique ID to every character that was ever created in the document. In order to ensure that documents can always converge, the CRDT model preserves this metadata even when characters are deleted.
This seems to be particularly expensive in dynamic languages like JavaScript.
Other languages allow you to efficiently represent all those characters and IDs
in-memory using
structs
(e.g. C or Rust). In JavaScript, everything is represented as an Object -
basically a key-value map that needs to keep track of all its keys and values.
CRDTs assign multiple properties to every single character in the document to
ensure conflict resolution. The memory overhead of merely representing a
document as a CRDT could be immense.
Every user-interaction creates more metadata that the CRDT needs to retain in order to ensure conflict resolution. It is not uncommon that CRDTs create millions of objects to store all this metadata. The JavaScript engine manages these objects on the heap, checks if they are referenced, and, if possible, garbage collects them. Another major problem is that with an increasing number of object creations, the cost of creating additional objects increases exponentially. This is shown in the following graphic:
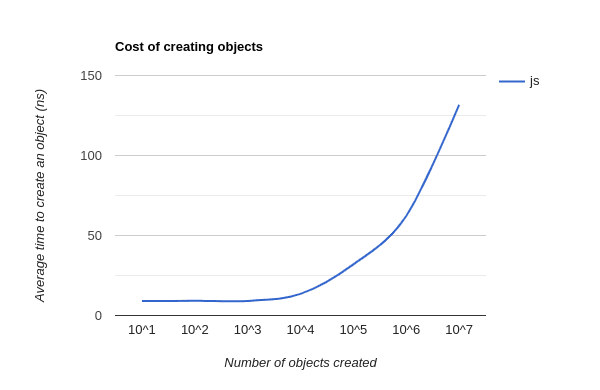
So the question arises if CRDTs are actually suitable for shared editing on the web, or if they impose a too significant cost to be viable in practice.
In case you don't know me, I'm the author of a CRDT implementation named Yjs, that is specifically designed for building shared editing applications on the web.
In this article, I will introduce you to a simple optimization for CRDTs and examine the exact performance trade-off of using Yjs for shared editing. I hope to convince you that the overhead is actually very small even for large documents with long edit histories.
Yjs
Yjs is a framework for building collaborative applications using CRDTs as the data model. It has a growing ecosystem of extensions that enable shared editing using different editors (ProseMirror, Remirror, Quill, CodeMirror, ..), different networking technologies (WebSocket, WebRTC, Hyper, ..), and different persistence layers (IndexedDB, LevelDB, Redis, ..). Most shared editing solutions are tied to a specific editor and to a specific backend. With Yjs, you can make any of the supported editors collaborative and exchange document updates through your custom communication channel, over a peer-to-peer WebRTC network, or over a scalable server infrastructure. My vision for this project is that you can simply compose your collaborative application using the technologies that make sense for your project.
This is not just some cool prototypical side-project. Yjs is a battle-proven technology that is used by several companies to enable collaboration. I'm only mentioning my sponsors here:
- Nimbus Note scales collaborative note editing horizontally using Yjs.
- Room.sh is a meeting software that allows collaborative editing & drawing over WebRTC.
I maintain a reproducible set of benchmarks that compares different CRDT
implementations. Yjs is by far the fastest web-based CRDT implementation with
the most efficient encoding. In this article I will often refer to specific
benchmarks contained in the crdt-benchmarks repository as, for example,
[B1.11].
Data Representation
Chances are you're already familiar with the general concepts of how CRDTs work. If not, and you want to dive into this rabbit hole, I recommend this fun interactive series:

A fun interactive series about CRDTs
Good entry point to find more CRDT related resources
The concept paper that describes Yjs' conflict resolution algorithm YATA is available on Researchgate. The concepts discussed here are pretty generic and could be extended to almost any CRDT.
In order to determine the performance cost, we are are going to examine how Yjs maintains data. Please bear with me while I describe how the CRDT model is represented using JavaScript objects. This will be relevant later.
Similarly to other CRDTs, the YATA CRDT assigns a unique ID to every character. These characters are then maintained in a doubly linked list.
The unique IDs are Lamport Timestamps. They consist of a unique user identifier and a logical clock that increases with each character insertion.
When a user types the content ABC from left to right, it will perform the
following operations: insert(0, A) • insert(1, B) • insert(2, C). The linked
list of the YATA CRDT, which models the textual content, will look like this:
CRDT model of inserting content ABC (assuming the user has the unique client identifier 1)
Notice how every character can be uniquely identified by the combination of the unique client-id and an ever-increasing clock counter.
Yjs represents the items of the linked list as Item objects that contain some content (in this case a String), a unique ID, the links to the adjacent Item objects, and additional metadata that is relevant for the CRDT algorithm.
All CRDTs assign some kind of unique ID and additional metadata to every character, which is very memory-consuming for large documents. We can't get rid of metadata as it is necessary for conflict resolution. Yjs also uniquely identifies each character and assigns metadata, but represents this information efficiently. Larger document insertions are represented as a single Item object using the character-offset to uniquely identify each character individually. The below Item uniquely identifies character A as { client: 1, clock: 0 }, character B as { client: 1, clock: 1 }, and so on..
Item {
id: { client: 1, clock: 0 },
content: 'ABC',
...
}
Yjs's internal representation of items in the linked list
If a user copy/pastes a lot of content into the document, the inserted content is represented by a single Item. Furthermore, single-character insertions that are written from left to right can be merged into a single Item. It is just important that we are able to split and merge items without losing any metadata.
This type of compound representation of the CRDT model and its split-functionality have first been described in A string-wise CRDT algorithm for smart and large-scale collaborative systems. Yjs adapts this approach for YATA and also includes functionality to merge Item objects.
The Cost of Operations
With this simple optimization in mind, let's have a look at how the number of modifications on a document relates to the amount of metadata that needs to be retained. We will measure metadata by the amount of Item objects created and later examine what the cost of a single Item is.
Every user interaction with a text editor can be expressed as either an insert or a delete operation.
insert(index: number, content: string)Insertions of any size create a singleItemthat is integrated into the document. In some cases the integration requires to split an existingItem. So we have a maximum of twoItemcreations per insertion.delete(index: number, length: number)Deleting anItemonly marks it as deleted. I.eitem.deleted = true. Therefore,Itemdeletions are free and will reduce the amount of memory used because theItem.contentcan be removed. TheItemdoesn't need to retain the content for doing conflict resolution. But deleting a range of content might require to split two existing items. Therefore, the cost of deletions is a maximum of twoItemcreations also.
By using the compound representation of CRDTs, the amount of metadata only relates to the amount of operations produced by a user. Not to the amount of characters inserted. This makes a huge difference in practice. Most larger documents are created by copy-pasting existing content or by moving paragraphs to other positions. Any kind of operation, even copy-paste and undo/redo, only create at most two Item objects.
Yjs also supports rich-text and structured documents. The above statement, that the amount of metadata only relates to the amount of operations, still holds true for these kinds of documents. But measuring operation-cost for more complex operations is out of scope of this article. An interesting observation in practice is that the document size of long-running editing sessions on structured documents (e.g. using the y-prosemirror binding to the ProseMirror editor) is actually much smaller than in linear text documents. This is due to other optimizations that play a role in Yjs and might be examined in another blog-post.
Measuring Performance
It has become common practice in academic research to measure performance by the amount of (concurrent) operations per second that a CRDT can handle. This might be an important benchmark for database applications that have a high throughput. But in shared editing applications, a relatively small number of users will produce just a few operations per second. So it doesn't matter if the integration process of a single operation takes one nanosecond or one hundred nanoseconds. Furthermore, conflicts rarely happen because most CRDTs address characters relatively, and a conflict only occurs if two users insert a character at the same position at the same time.
When we only use a specific scenario (e.g. number of insertions at random positions) to benchmark performance, we might end up with a CRDT that only performs well in this specific scenario. In practice, other performance characteristics also play a role. I try to capture relevant performance characteristics in different scenarios in the crdt-benchmarks repository. It shows that some CRDTs perform well in some scenarios, but perform poorly in others. As an example, the RGA implementations perform well when appending content, but have very bad runtime behavior when content is only prepended. A CRDT for shared editing should perform well in all scenarios. The below list describes the lifetime of a shared editing application and gives more insight into the relevance of different performance characteristics.
- The document is loaded from the network or from a local file. Parsing an encoded document often takes a considerable amount of time, especially if the document is large.
parseTimedenotes the time it takes to parse an encoded document. In my opinion,parseTimeis the most important performance characteristic because it blocks the process at the start of the application. All other tasks can be performed while the user is not working. - The document is synced with other peers. If the document was modified while offline, conflicts may occur. The [B2] benchmarks measure sync conflicts produced by only two clients (e.g. in a client-server environment). The [B3] benchmarks measure the time it takes to sync conflicts between multiple clients (sync conflicts that may occur in a p2p environment). In most CRDT implementations, sync conflicts need to be resolved again when the document is loaded; so pay special attention to
parseTimewhen looking at the benchmarks. - A user applies changes to the local document. Yjs uses a linked list to represent characters in the document. Unless the editor directly works on the CRDT model, the editor will apply
insertanddeleteoperations using index-positions. The CRDT implementation needs to traverse its internal representation to find the position, perform the change, and then produce an update that is sent to other peers.timedenotes the time it takes to perform a certain task (e.g. append one million characters, sync N concurrent changes, ..). The [B1] benchmarks simulate a single user performing changes on a document without actually producing conflicts. It shows that some CRDTs have a significant overhead when it comes to simply applying changes on a document. - Collaborators send document updates to remote peers. We assume that applying a single update on a remote peer doesn't take a considerable amount of time. Applying several operations is covered by the [B2] and [B3] benchmarks. Most CRDT implementations support some form of incremental update functionality. Each change produces a small update that is sent to other peers.
avgUpdateSizedenotes the average size of a document update. It simply confirms that a CRDT produces small incremental updates. - The document is stored in a database or sent to remote peers.
encodeTimedenotes the time it takes to transform a document to a binary representation.docSizedenotes the size of the encoded document.
The crdt-benchmarks readme shows the performance characteristics of many different scenarios that are relevant for shared editing. In this article, we just cover a few benchmarks measuring the most relevant performance characteristics:
memUsedThe heap-size of the JavaScript engine after all changes are applied. In the crdt-benchmarks repositorymemUsedis just an approximation of the memory used, because we can't run the garbage-collector reliably to remove traces of previous benchmarks. I ran the benchmarks of this article individually and measured the heap size directly in the performance inspector to get a more accurate result.docSizeThe size of the encoded document. Yjs has a very efficient encoder that writesItemobjects to a binary compressed format. It is sent over the wire (WebSocket, HTTP, WebRTC, ..) to other clients, so we want to make sure that the document size is reasonable.parseTimeThe time it takes to parse the encoded document. After we received the encoded document from the network, we want to render it as soon as possible. So we expect that it is parsed within a reasonable amount of time.
A worst-case scenario
In the best-case scenario for Yjs, a user writes content from left to right. In this case, all operations are merged into a single Item.
The absolutely worst-case scenario is a user writing content from right to left. This scenario accurately reflects the performance overhead of Yjs without its compound optimization. Please note that this scenario doesn't occur naturally, as even right-to-left writing systems (e.g. Hebrew) store data in its logical order (left-to-right).
How many insert operations do users usually produce when writing large documents? If I wrote Yjs from scratch in a single file, I would write around 200k characters. The whole CodeMirror source code consists of 568k characters. Well, let's say Yjs would need to handle one million insert operations while writing from right to left. That amounts to one really large document. How bad is it?
We are afraid that Yjs uses too much memory to represent all those Item objects. After all, memory usage in JavaScript seems to be inefficient, and we also have to worry about the exponential increase in time to create JavaScript objects.
In order to benchmark the worst-case scenario, we are going to create one million Item objects by producing one million single-character insert operations at position 0:
import * as Y from 'yjs'
const ydoc = new Y.Doc()
const ytext = ydoc.getText('benchmark')
// Insert one million 'y' characters from right to left
for (let i = 0; i < 1000000; i++) {
ytext.insert(0, 'y')
}
// transform ydoc to its binary representation
const encodedDocument = Y.encodeStateAsUpdateV2(ydoc)
const docSize = encodedDocument.byteLength
console.log(`docSize: ${docSize} bytes`) // => 1,000,046 bytes
// Measure time to load the Yjs document containing 1M chars
const start = Date.now()
const ydoc2 = new Y.Doc()
Y.applyUpdateV2(ydoc2, encodedDocument)
const parseTime = Date.now() - start
console.log(`parseTime: ${parseTime} ms`) // => 368.39 ms
Benchmark the time to parse a document containing one million character insertions without optimizations. Equivalent to [B1.3] with N=1,000,000
Results
memUsed: 112 MBdocSize: 1,000,046 bytesparseTime: 368.39 ms
It turns out that the worst-case scenario is not too bad at all. Yjs doesn't consume an excessive amount of memory. I would say that the overall memory consumption of 112 MB is pretty bearable, considering the amount of changes that are applied to the document. Parsing a document of that size in less than 400 ms also doesn't seem that bad. And please keep in mind that this is the absolutely worst-case scenario for Yjs.
I showed that the amount of metadata is only related to the amount of changes produced and not to the amount of content inserted. To put one million insertions in perspective: A keyboard stress test machine would need 139 hours at 120 keystrokes per minute to generate one million insertions.
Examining memory usage
JavaScript objects work like key-value maps. That would mean that each object needs to keep track of all its keys and map them to their respective value. A C-struct doesn't need to retain the keys in-memory and only holds the values in an efficiently encoded format. So naturally, there is a lot of fear when working with a lot of objects in JavaScript. But object representation in JavaScript engines is actually pretty efficient. When you create many objects with the same structure (they all have the same key entries), the JavaScript engine represents them almost as efficiently as C-structs. In V8/Chrome this optimization is known as hidden classes. In SpiderMonkey/Firefox the same optimization is referred to as shapes. This type of optimization is literally older than the web and part of all JavaScript runtime engines. So object representation is not something we need to worry about.
A light overview of how V8 optimizes JavaScript code
Lets' jump back to the worst-case scenario and examine how much memory exactly each Item consumes.

Screenshot of the memory inspector when creating one million items
An Item consists of some content (in this case ContentString) and an ID object. The ID, in turn, consists of an ever-increasing numeric clock and a numeric client identifier that doesn't change in this scenario. Hence, we only have a bit over one million (number) objects. Therefore, the cost of each Item is 88 bytes of memory usage, excluding its content. You get this number by adding up the Shallow Size for Item, ID, and (number)and divide that by the amount of items. Each ContentString object consumes 16 bytes in addition to the size of the inserted string.
Another 5.2 Mb is used to index these items only using Arrays. Generally, the amount of indexing information needed is negligible compared to the amount of items created.
The performance of a web-based CRDT implementation is directly tied to the amount of objects that it creates. Analyzing the runtime performance of the worst-case scenario, we can observe that 40% of the time is spent performing V8 memory cleanups (Major & Minor GC).

Time spent when creating one million items
This is a big drawback of dynamic programming languages. However, in the following section we will see that our optimizations reduces the number of object creations in practice, and therefore also improves performance significantly.
A real-world scenario
Yjs is optimized for human input behavior. A quite obvious observation is that text is usually inserted from left to right. And although we often need to correct spelling mistakes, we tend to delete the whole word and then start again. Yjs takes advantage of this behavior and optimizes bulk insertions by representing consecutive insertions in a single Item. Copy-pasting a huge text-chunk into the document also just creates a single Item. Furthermore, deletions are free and reduce the amount of memory used. These optimizations make a huge difference in practice, as we can see in a real-world scenario.
Martin Kleppmann shared the editing trace of text operations that he created when he wrote his 17 page long conference paper on A Conflict-Free Replicated JSON Datatype. The editing trace consists of 182,315 single-character insertions and 77,463 single-character deletions. The final document contains 104,852 characters (including white space).
The benchmark results [B4] of applying the editing trace on a Yjs document confirm my prediction that humans usually produce bulk insertions:
memUsed: 19,7 MBItemobjects created: 10,971
• 5,799 contain content
• 5,172 are marked as deleted and don't contain any contentdocSize: 159,927 bytesparseTime: 20 ms
A naive implementation would represent each of the 260k single-character insertions/deletions as a separate JavaScript object. In Yjs, the complete document structure consists of only 11k Item objects. The actual amount of memory used is about 2.1 MB. The rest is used for V8 internal code optimizations (the next benchmark confirms that).
The encoded document has a size of roughly 160 kB. A small overhead of only 53% on the document size won't impact network performance even for slow network devices. Actually, Yjs might be favorable compared to other solutions, because it allows you to store documents in the browser database so that you only need to pull the differences from the network. This works even without a central authority to manage editing history.
Parsing the editing trace of a complete conference paper in 20 ms is fine. Even though the overhead of parsing in a centralized shared editing solution is close to zero, I would argue that the benefits of decentralization outweigh an overhead that is unnoticeable in practice.
Parsing Huge Documents
The real-world scenario shows that Yjs doesn't have any significant overhead when working with moderately sized documents like scientific papers. But what about writing really large books with Yjs. Surely, the time to parse such large documents will increase exponentially. At the beginning of this article I gave benchmark results that show that the time to create objects increases exponentially with the amount of objects already created. Furthermore, data structures that index the items should result in at least a logarithmic increase in time.
The benchmark [B4 x 100] shows that the time to parse the document only increases linearly with the amount of operations. I applied the same editing trace of over 260k insert and delete operations one hundred times resulting in one enormous document. The time to parse this document only increases linearly (20 ms * 100).
memUsed: 220 MBdocSize: 15,989,245 bytesparseTime: 1952 msItemobjects: 1,097,100
The final document contains 10,485,200 characters (18 million insert operations and 8 million delete operations). Again, to put this in perspective: The novel A Game of Thrones: A Song of Ice and Fire only contains about 1.6 million characters (no pun intended).
At 30 characters per minute, a human would need 1.65 years of non-stop writing to to produce 26 million operations. This doesn't even account for cursor movements to produce fragmentation in the document. Yjs comfortably handles 26 million changes using only 220 MB of memory.
This benchmark shows that Yjs can handle ridiculously large documents and that the time to parse a document only increases linearly, not exponentially as we suspected. Even in this scenario the performance overhead of Yjs is barely noticeable. Pulling a large document with a size of 10 MB from the network and rendering it in the browser will take significantly longer than parsing the document with Yjs.
The exponential increase in time to create objects doesn't really affect Yjs because it creates very few objects to begin with. Tests confirm that you need to apply the real-world dataset 1000 times to create 10 million items that incur an additional garbage-collection overhead of one second to parse the document. Up to this point, the time to parse the document will only increase linearly.
As for the data structure that index the Item objects, the time to perform queries indeed increases logarithmically with the amount of items already inserted. However, the overhead is so insignificant that you won't be able to measure it. I also suspect that the JavaScript engine gradually optimizes the executed code and cancels out the logarithmic overhead. In practice, the time to parse documents only increases linearly with the amount of user-interactions.
Conclusion: Are CRDTs suitable for shared editing?
Absolutely! It is basically impossible for a human to write a document that Yjs can't handle. I showed exhaustively that Yjs performs exceptionally in real-world scenarios and even performs well if none of the optimizations can be applied.
The performance trade-off that Yjs imposes is very favorable. In exchange for a small amount of memory per operation, Yjs allows you to sync documents with other peers over any networking stack - even peer-to-peer. Of course, it also has other features that are relevant for shared editing:
- Selective Undo/Redo manager
- Snapshots and being able to revert to an old document state
- Computing the differences between versions and render diffs by the user who created the changes (git blame)
- Syncs changes to a browser database to allow offline editing
- A collaboration-aware model to represent positions like cursor locations
- Awareness functionality (who is currently online, what are they working on, ..)
In my opinion, the slight overhead that we examined is worth the benefits of having a collaboration-aware model that works in distributed environments.
If you'd like to know more about Yjs, head over to GitHub and follow me on twitter to get notified about the latest developments.
Maintaining Yjs, caring for GitHub issues, and managing a growing community takes up a lot of my free time. If you would like me to do more public work, such as writing blog articles, then please fund me on GitHub Sponsors:

In the next blog post I'd like to address the notion that CRDTs increase the complexity of an application. Yjs has a collaboration-aware model that is very helpful for implementing features such as commenting, shared cursors, position markers, presence, or suggestions on collaborative (rich)-text documents. Implementing a CRDT like Yjs including its optimizations correctly is not trivial. I will discuss methods that I use to test distributed systems that give me a high confidence that documents will always converge.
Notes:
- Recent publications describe Yjs as a CRDT that performs some kind of garbage collection scheme to collect tombstones to reduce the size of the document. The document size only decreases because of the optimizations that are laid out in this article. Yjs doesn't perform a garbage collection scheme that would result in convergence issues. To be fair, my first publication in 2016 described a garbage collection scheme including its limitations. The mentioned garbage collection scheme did work as intended, but was never enabled by default because it, as it was described, only works under specific circumstances and needed more work. The garbage collection approach has been removed in 2017 and replaced by a compound representation to improve performance. This article shows that tombstone garbage collection is not even necessary for CRDTs to work in practice.
- It is often claimed that CRDTs are faster than OT. I explained before that academic research mostly measures performance in ops/second, which doesn't really reflect the requirements of shared editing applications. In practice, several CRDTs are unsuitable for shared editing because they don't perform well in certain scenarios. Centralized approaches have an edge over CRDTs when it comes to
parseTime. In ShareDB, for example, the document is sent to the client with little additional metadata and the document can be parsed much faster. Decentralized approaches send additional metadata that incur a parsing overhead. However, this article shows that this overhead is not that significant in Yjs.
Edits:
- 12/30/2020 - Updated argument about right-to-left writing systems. Previously, I was concerned that Yjs won't work well in right-to-left writing systems (e.g. Hebrew, and Arabic) because the compound optimization only applies to text that is written from left to right. But a user mentioned to me that editors always store document content in logical order (left-to-right) even if the used writing system is right-to-left.